



はじめに
こんにちは。AD-Tech事業部のトゥンでございます。
機械学習の手法である教師なし学習の一番簡単なアルゴリズムとサンプルを紹介いたします。
K-meansクラスタ分析とは
K-meansクラスタ分析( K-means Clustering)はデータのラベルがわからない場合、同じ属性があるデータを同じクラスタに分割するアルゴリズムです。
アルゴリズムの解析
-
最初に、分類の起点として、各クラスタの重心(核)をK個生成します。
重心は任意の値でも良いし、入力データの一部でも良いです。(ここでは4個)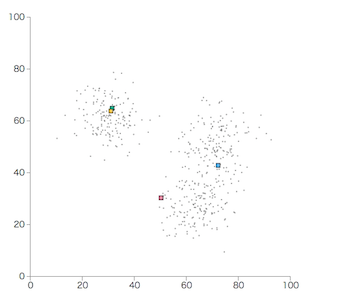
-
それぞれの重心との距離を基に、データをクラスタに分類します。
各データは、一番近い距離にある重心のクラスタに所属します。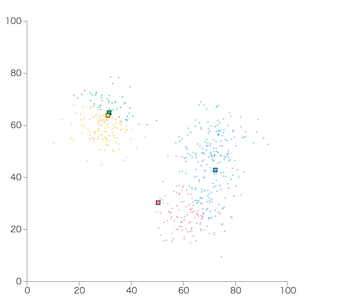
-
各クラスタに所属するデータの平均値を新しい重心にします。
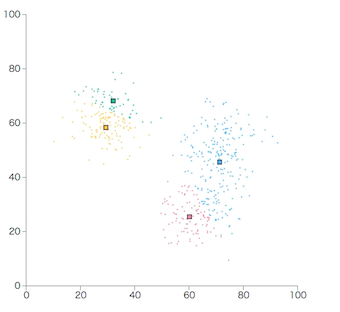
-
新しい重心が決まったところで、「2.」に戻って同じことを繰り返します。
-
重心が変化しなくなるまで繰り返します。
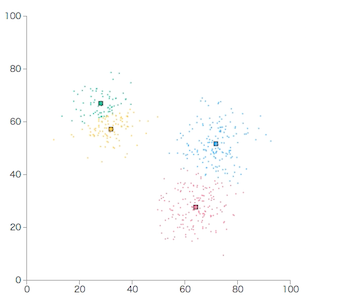
重心が変化しなくなっていき、収束することが証明されています。証明はこのドキュメントを参照してください。
K-meansクラスタ分析の各ステップの挙動
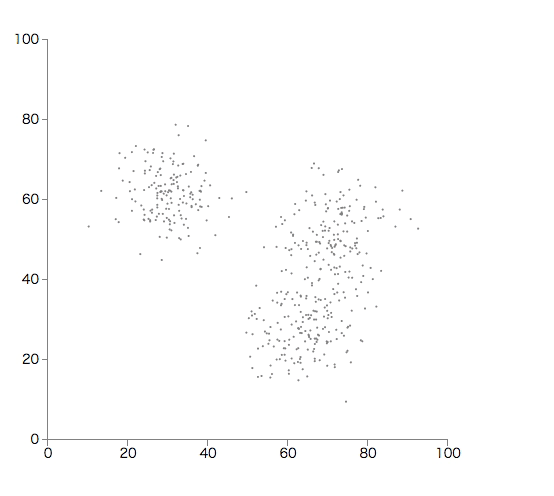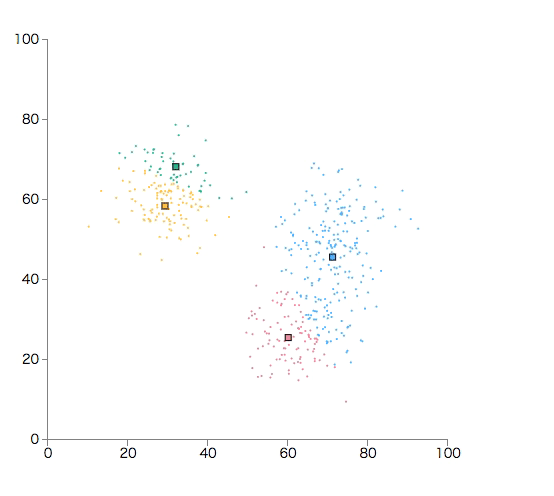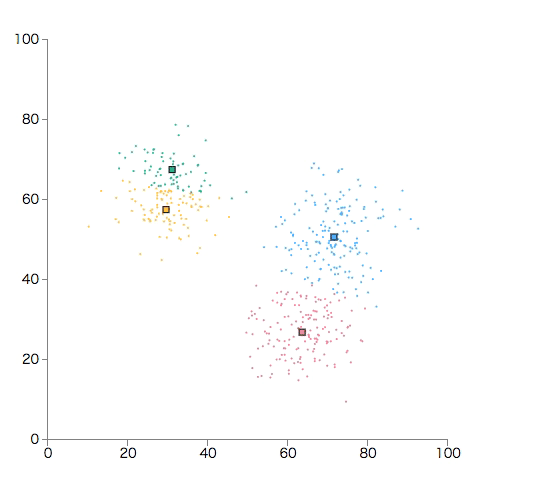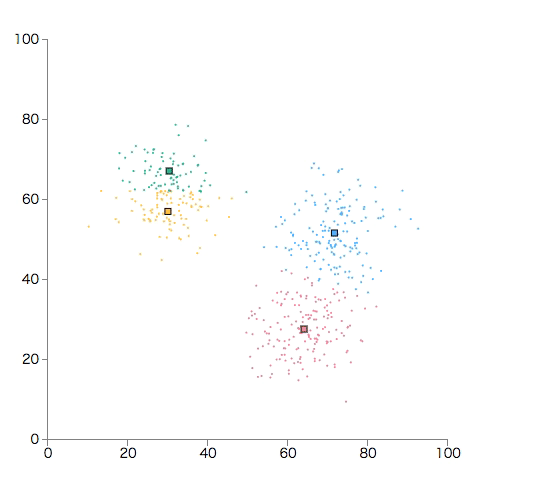
簡単なサンプルを作ってみる
手書きの数字をクラスタリング
MNIST文字データ
MNISTとは、「Mixed National Institute of Standards and Technology database」の略で、手書きの数字「0~9」に正解ラベルが与えられているデータセットです。
手書き文字は28ピクセル×28ピクセル(784ピクセル)の画像で与えられます。ピクセルごとに0~255までの値があります、黒いピクセルの値は0、ピクセルが白ければ白くほどピクセルの値は255に近くなります。
トレーニングセットは0~9の画像が6万サンプルありまして、テストセットは1万画像があります。全てのデータの画像はラベルが付けられています。
以下はMNISTデータのサンプルです。

(Simple Neural Network implementation in Ruby からの画像)
問題:仮にMNISTのデータ画像のラベルがわからない場合、同じ数字がある画像を同じクラスタに分類します。
K-meansクラスタ分析を使って上記の問題を解決しましょう!
まずはこのリンクからMNISTデータをダウンロードします。
Pythonでコードを書きます。
以下のコードはテストデータ(1万画像)をクラスタリングします。
|
1 2 3 4 5 6 7 8 9 10 11 |
from mnist import MNIST // MNIST読み込むライブラリー from sklearn.cluster import KMeans mndata = MNIST('data/') // MNISTデータを読み込む mndata.load_testing() // MNISTデータからトレーニングデータを読み込む test_imgs = mndata.test_images // トレーニング画像を読み込む K=10 // 0-9:10クラスタ kmeans = KMeans(n_clusters=K).fit(test_imgs) pred_label = kmeans.predict(test_imgs) |
Object Segmentation
問題:以下の画像から花があるピクセルを区別します。

解説:この画像では、花は白、バックグラウンドは青と黒と、主に3つのカラーがあります。
それで3クラスタにしたらお花のところは機械でわかるようになるはずです。
やりかたとしてはまず画像ピクセルごとを3クラスタに分類し、その後に画像ピクセルごとに分類されたクラスタの重心の値に切り替えます。
終わったら3色がある画像が出てきます。花のピクセルは全て白くなりますので、花のみを抽出したい場合は白いピクセル以外のピクセルを適当な値に設定することで抽出できるようになります。
Pythonでコードを書きます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import matplotlib.image as mpimg import matplotlib.pyplot as plt import numpy as np from sklearn.cluster import KMeans img = mpimg.imread('/Users/le_tung/Desktop/test.jpg') // 画像を読み込む X = img.reshape((img.shape[0], img.shape[1], img.shape[2])) // 画像のデータからピクセルのマトリックスに変換 K=3 // 3カラーでクラスタリング kmeans = KMeans(n_clusters=K).fit(X) label = kmeans.predict(X) img4 = np.zeros_like(X) // ダミー画像のピクセルマトリックスを生成 for k in range(K): img4[label == k] = kmeans.cluster_centers_[k] // ピクセルごとを重心の値に切り替える img5 = img4.reshape((img.shape[0], img.shape[1], img.shape[2])) // 正常な画像データに変換 plt.imshow(img5, interpolation='nearest') // 結果の画像を表示 plt.axis('off') plt.show() |
結果は3つ色がある画像になります。

花のみの画像が欲しい場合、K=1のみを重心のカラーに設定して、他のピクセルは適当な値にすると結果が出します。
|
1 2 |
img4[label == 1] = kmeans.cluster_centers_[1] // お花のピクセルのみ重心の値をセット img4[label != 1] = 0 // 他のピクセルは黒くする |
結果:

こんにちは!トゥンと申します。開発しながら学んだことを共有していこうと思います。



